2026-02-25
Many people report these phenomena:
- Childhood felt long.
- Adulthood feels compressed.
- A week in a radically unfamiliar environment can feel unusually “dense” in memory.
Now that I’m pushing 50, a year feels like one quarter from when I was 10, which makes me wonder:
How fast time will go by when I’m 75?
Will a year go by in an eye-blink?
The usual explanation for the phenomena above is that “Retrospective time (how long it feels in memory) scales with how many genuinely new things you learn”. That is, if little is learned, calendar time still passes, but it leaves fewer distinct memory traces.
That’s fair, but this explanation doesn’t answer my question, it just predicts that time at age 75 will go by even faster. Yeah, but how much faster?
I also don’t need a complete cognitive theory of time perception. A simple minimal toy that exhibits these phenomena should do. The point is to see whether a minimal novelty-counter produces a curve that resembles the usual “time speeds up” story.
A simple model of “registered time”
Imagine your mind maintains a growing vocabulary of concepts.
- Early in life, almost everything is new.
- Later, most experiences reuse existing concepts.
- Occasionally, you enter a new domain and learn many new concepts again.
If retrospective time corresponds to the moments when your internal vocabulary grows, then:
- early life should feel dense,
- later life should feel compressed,
- and novelty spikes should locally “stretch” remembered time.
The experiment
Treat words as stand-ins for “concepts.”
- Take ~12,000 English books from Project Gutenberg, which is about 830 million words, roughly a lifetime of reading at 30,000 words/day for 75 years.
- Shuffle the books into a random order.
- Feed them through a learner that “learns” a word the first time it appears.
- Track the number of distinct words seen so far.
Vocabulary growth in text is a classic result in quantitative linguistics: it’s sublinear (Heaps’ law). It slows down, but never completely stops.
What the curve looks like
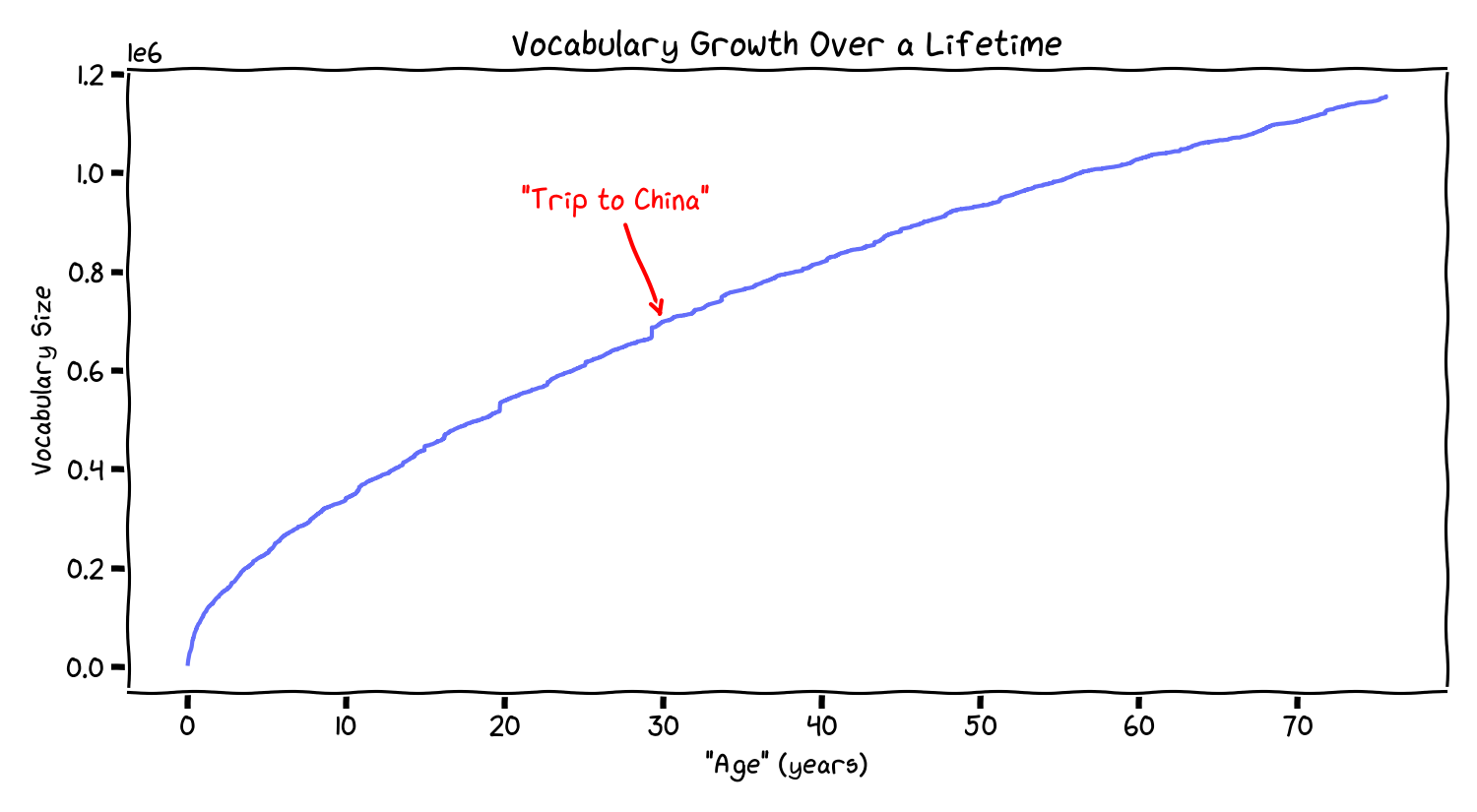
The curve is steep early and gradually flattens. In this corpus, by “age 10” you’ve already accumulated a large fraction of the eventual vocabulary; by 40 it is increasing slowly, and by 60 it’s even shallower. This is consistent with Heaps’ law. The only question is whether the rate curve resembles the way people talk about time.
The growth rate is the key quantity
If “remembered time” tracks novelty, the key thing is how many new words you learn per day.
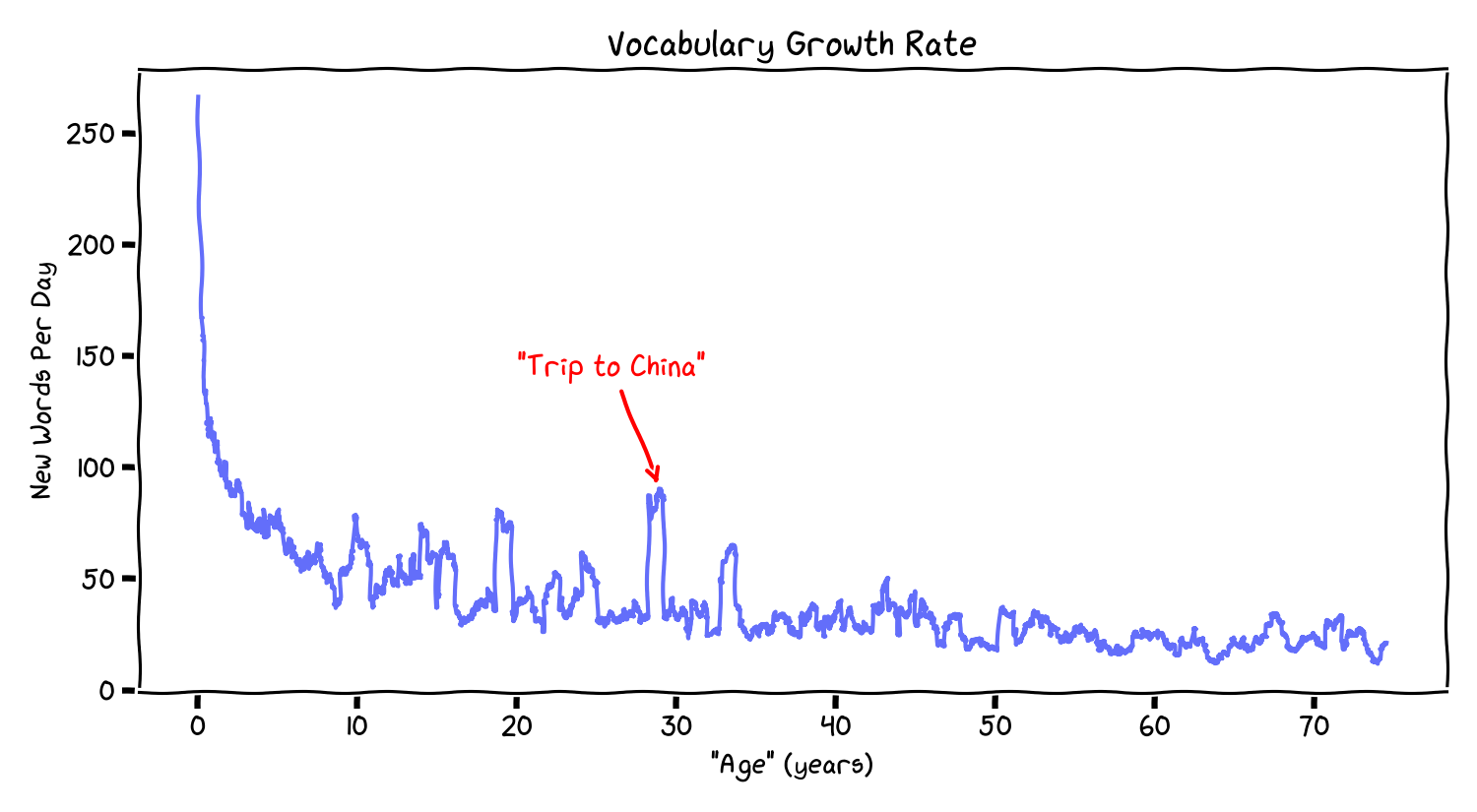
The rate falls sharply early, then tapers. In your run:
- early: hundreds of new words/day,
- later: tens of new words/day.
Also notice the lumps: the rate isn’t perfectly smooth (which diverges from the smoothness of Heaps’ ideal law). It spikes when the stream shifts into a slightly different domain (new author, genre, topic). In model terms, those are distribution shifts. This is consistent with the phenomenon that a 10-day trip to an exotic place (like China if you’re me) can feel much longer.
A proxy for “How compressed is time?”
Here’s one simple compression metric:
Define
D(age)= the number of calendar days needed (at that age) to accumulate 100 new words.
If 100 new words is a crude proxy for “a unit of memorable novelty”, then larger D means the same amount of novelty takes longer to arrive, so
time compresses in memory.
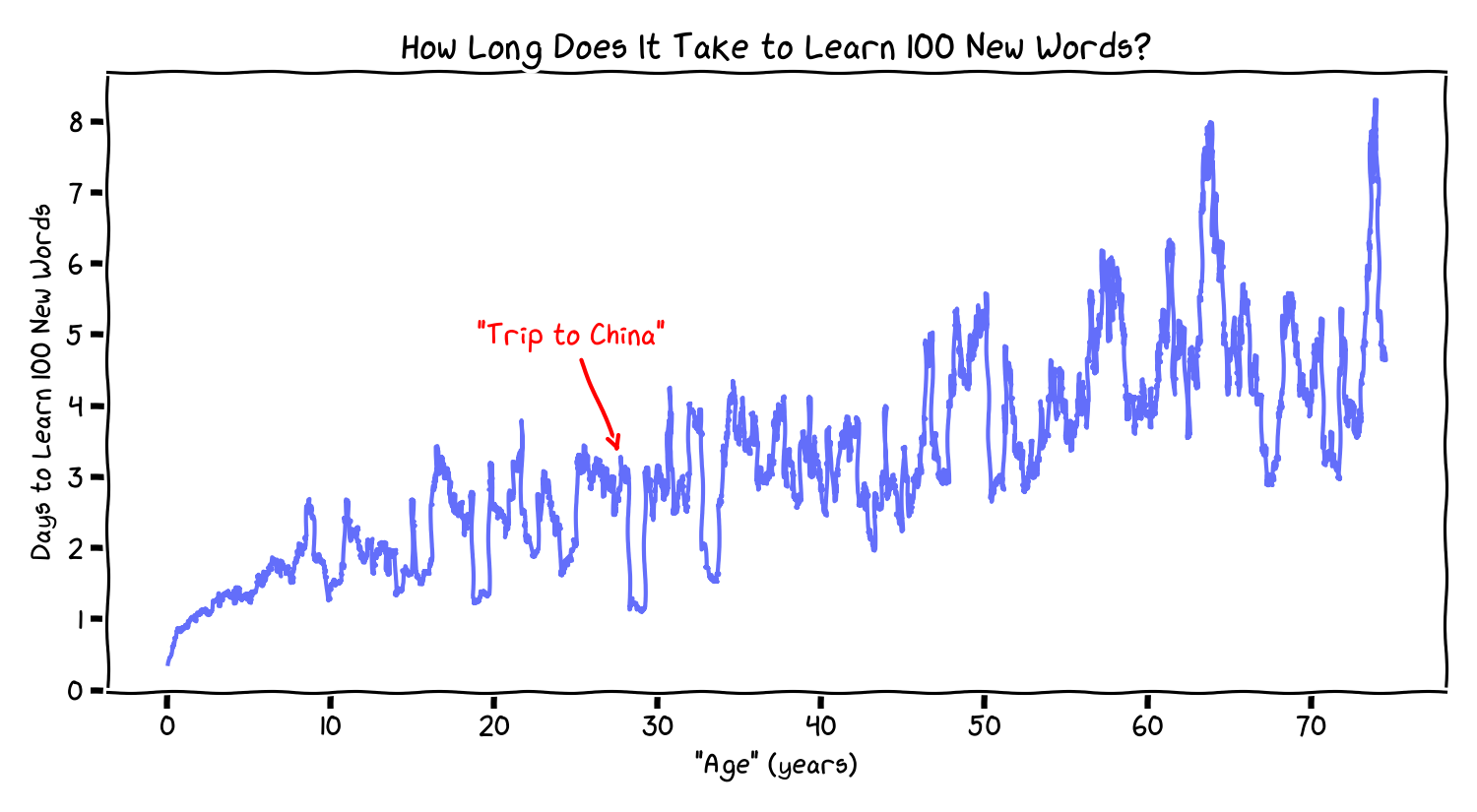
Reading this plot:
- At “age 1,” it’s <1 day per 100 new words.
- At “age 10,” ~1.5 days per 100.
- At “age 50,” ~4 days per 100.
- At “age 75,” ~5-6 days per 100.
This yields a direct toy-model answer to the title question: a year at 75 will be seem to go roughly 20-50% faster than at age 50.
This is a bit heartening to me. If we assume real-world concepts follow a similar distribution as given by Heaps’ law, then it’s not another 4X, where every day is Groundhog Day, and the routines make time compress to nothing.
Routine vs. an out-of-distribution week
The lumps in the growth-rate curve suggest a real-world prediction:
A week in a stable routine:
- reuses familiar concepts,
- adds little new “vocabulary,”
- leaves fewer distinct memory anchors.
A week in a genuinely unfamiliar setting (travel is one way; switching jobs/domains is another):
- forces new cues and new prediction errors,
- adds more new “vocabulary,”
- leaves more anchors.
In model terms, you changed the input distribution. The novelty rate spikes. Retrospective time feels “expanded”.
Aging through this lens
This toy model suggests:
- Childhood: lots of novelty -> dense remembered time.
- Adulthood: less novelty -> compressed remembered time.
- Life changes / new domains: novelty spikes -> locally expanded remembered time.
Time doesn’t feel fast because “nothing happens” in an objective sense. It feels fast because fewer things are distinct enough to be remembered as separate events.
What this is (and isn’t)
This is not a claim that:
- the brain literally stores words,
- language is the only driver of memory,
- or this is a full theory of time perception.
It is:
- a minimal computational proxy for novelty accumulation,
- grounded in known corpus statistics (Heaps’ law / Zipf-like behavior),
- that produces the right qualitative curve shape,
- and makes a falsifiable-ish prediction: novelty spikes should correlate with “expanded” retrospective time.
Practical implication (if you buy the toy model)
If novelty accumulation is even part of the story, then you can’t stop the long-run slowdown, but you can change the local slope by doing things that reliably force learning:
- new domains, skills, or roles
- reading outside your genre
- new social environments
- travel (as one blunt instrument for distribution shift)
Not because “travel is magic”, but because it can be one way to force sustained prediction error.
Appendix: Does the order of books matter?
The corpus used here is the English-language portion of Project Gutenberg, available for bulk download via their offline catalogs and mirror sites.
What if, instead of encountering books randomly, you always read the easiest next book–the one that introduces the fewest new words? This is a greedy “easy-first” curriculum, roughly analogous to maximizing routine.
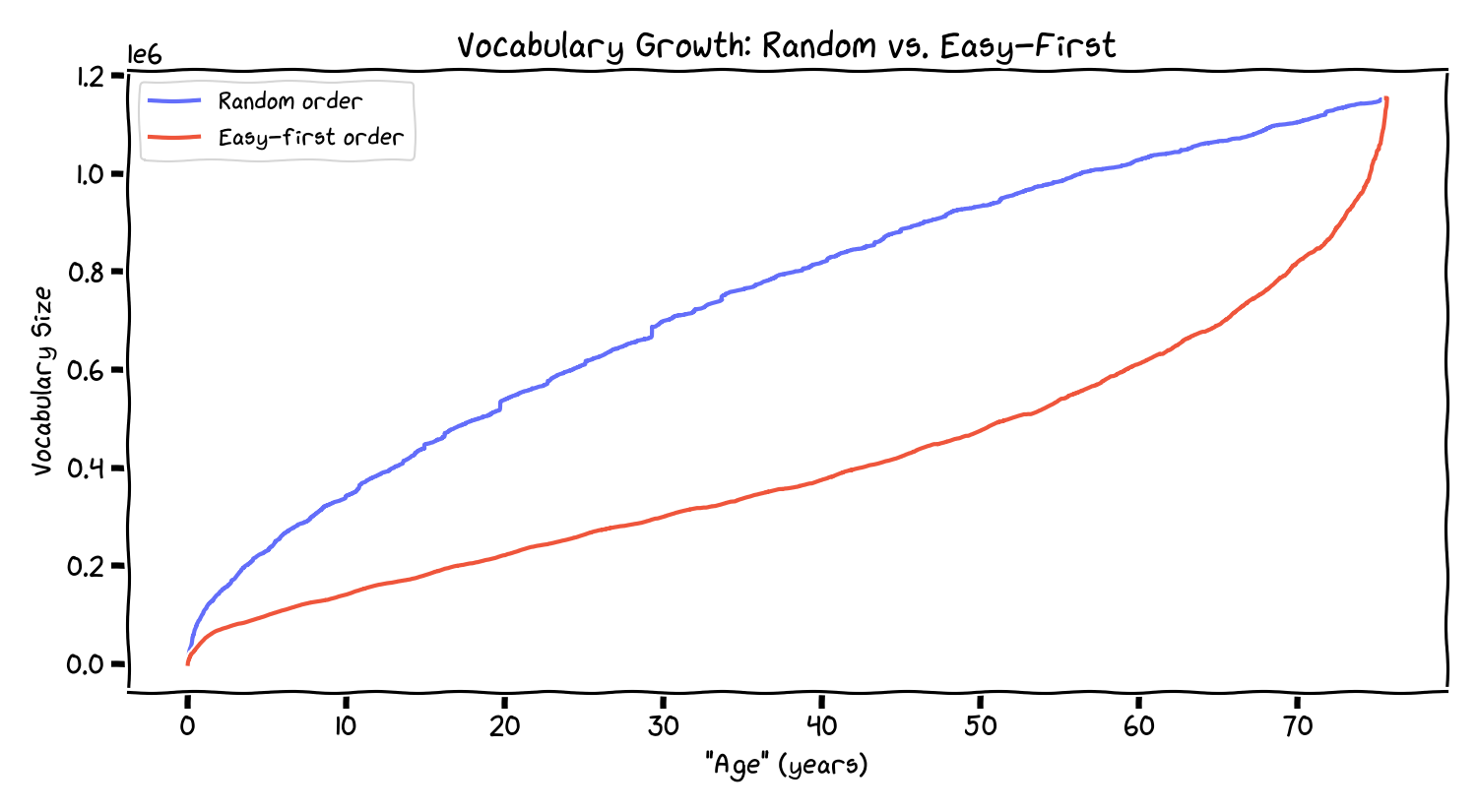
The random curve (blue) has the familiar sublinear shape. The easy-first curve (red) stays nearly linear for a long time (because it keeps selecting redundant texts), then spikes late when it runs out of easy choices.
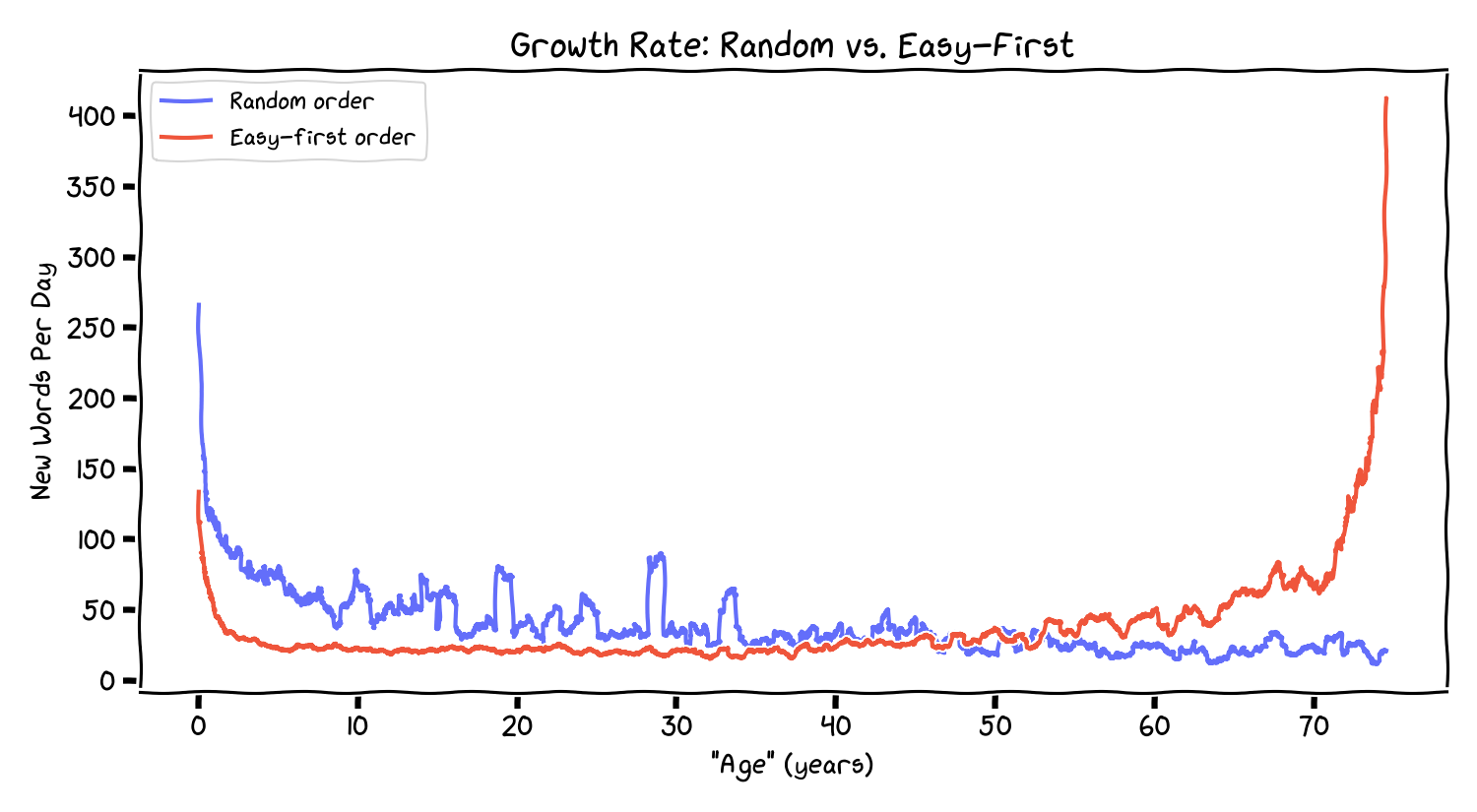
In this framing, an “easy-first life” is one that defers novelty. The novelty doesn’t disappear; it accumulates behind a wall of routine until you hit a forced distribution shift.
Runnable code
import os, random, plotly.express as px
gutendir = "~/gutenberg/eng/" # directory of .txt files
random.seed(42)
all_files = sorted(os.listdir(os.path.expanduser(gutendir)))
random.shuffle(all_files)
vocab, points, token_i = set(), [], 0
while token_i < 1_000_000_000 and all_files:
fname = all_files.pop()
with open(os.path.join(os.path.expanduser(gutendir), fname), "r", encoding="utf-8") as f:
try: text = f.read()
except UnicodeDecodeError: text = ''
text = "".join(c if 'a' <= c <= 'z' else ' ' for c in text.lower())
words = text.split()
for word in words:
if word not in vocab:
# A "learning" event!
vocab.add(word)
points.append((token_i, len(vocab)))
token_i += 1
fig = px.line(
x=[x[0] for x in points], y=[x[1] for x in points],
labels={"x": '"Time" (Position in Text)', "y": "Vocabulary Size"},
)
fig.show()
References
- Heaps, H. S. (1978). Information Retrieval: Computational and Theoretical Aspects. Academic Press.
- Zipf, G. K. (1949). Human Behavior and the Principle of Least Effort. Addison-Wesley.
- Cover, T. M., & Thomas, J. A. (2006). Elements of Information Theory. Wiley.
- Anderson, J. R. (1990). The Adaptive Character of Thought. Lawrence Erlbaum. ```